Jobsystem¶
Einführung¶
Übersicht¶
Das Jobsystem ermöglicht in VLS lang-laufende Operationen (Jobs) zu verwalten. Solche Operationen können zum Beispiel Importe von Images oder Updates von vielen Datensätzen sein. Operationen, die nur wenig Zeit benötigen und daher synchron abgearbeitet werden können, werden im Gegensatz zu Jobs als Actions realisiert.
VLS bringt im Core etwa 100 verschiedene Jobs mit. In den
Domainverzeichnissen können weitere domain-spezifische Jobs im ./jobs
Verzeichnis abgelegt werden.
>>> len(component.vls.job.Jobs)
103
Jobs werden als Python-Klassen implementiert, die von einer
Job-Basisklasse abgeleitet sind. Zur Server-Startup-Zeit werden
bestimmte Dateien/Verzeichnisse gescanned und alle abgeleiteten Klassen
zentral in vls.job.Jobs registriert.
Konfiguration¶
Das Interface für Jobs wird über ein Konfigurationsformat im ini-style
mit Typdeklarationen definiert. Das Format verwendet dieselben
Konventionen wie das Format der Server-Konfiguration (server.ini).
class GenerationBackupDatabaseJob(BackupDatabaseJob):
"""Three generation backup of database
Generation 1: every weekday except Friday, backups are kept for 7 days
Generation 2: every Friday, backups are kept for 28 days
Generation 3: last day of every month, backups are kept for one year
"""
config_ini = """
# if the database is local and the directory for storing the backup file does not exist
# we will try to create it (and change permissions for fb process)
localDB = boolean(default=true)
# zip the resulting fbk
zip = option(gz, zip, false, default=gz)
# keep the unzipped file
keep = boolean(default=false)
"""
In der Implementierung der Jobklasse lässt sich auf die getypten Werte
dann zum Beispiel via self.config.keep zugreifen.
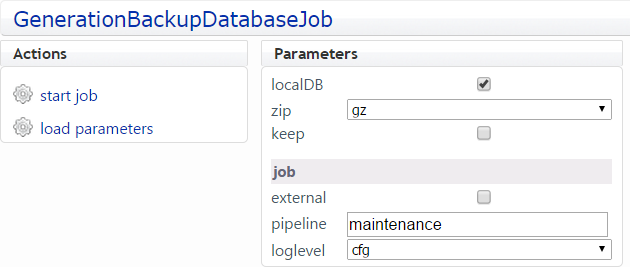
Auf der Adminseite /admin/jobs lässt sich vor dem Starten des
GenerationBackupDatabaseJob die Defaultbelegung der
Konfigurationsparameter noch verändern:
Über die HTTP-Schnittstelle lassen sich Jobs über einen Request in der
Form /action/startJob?name=GenerationBackupDatabaseJob&keep=true
starten. Die Jobkonfiguration wird über GET/POST Parameter gesetzt.
Normalerweise werden diese Requests über Aktionen auf dem Adminseiten
oder via VLM ausgelöst.
Im Pythonkontext werden Jobparameter als Keywords im Funktionsaufruf gesetzt:
component.vls.job.startJob('GenerationBackupDatabaseJob', keep=True)
Bei verschachtelten Parametern empfiehlt sich folgende Notation:
kwds = {'section1.option1': True, 'section2.option1': 99}
component.vls.job.startJob('GenerationBackupDatabaseJob', **kwds)
Scheduler¶
Der VLS-Scheduler ermöglicht es, Jobs zu bestimmten Zeitpunkten vom
Server ausführen zu lassen. Die Scheduler-Konfiguration findet sich in
der server.ini der VL-Instanz. Eine einfaches Beispiel, dass erst den
ImportJob und nachfolgend den IndexJob jeden Wochentag um 23:00
ausführt, sieht folgendermaßen aus:
[scheduler]
[[runImport]]
eventJob = ImportJob
eventDomain = ihd
eventTime = 23:00:00
eventWeekday = Mo,Tu,We,Th,Fr
[[runIndex]]
eventJob = IndexJob
eventAfter = runImport
mode = full # the only param that is fed into the job-api (config_ini)
Die Parameter eventDomain, eventJob, eventTime, eventWeekday und
eventAfter sind scheduler-spezifische Optionen, die steuern wann
der Job in welchem Domainkontext ausgeführt wird. Alle weiteren
job-spezifischen Parameter, wie hier mode = full werden an das
Jobinterface weitergereicht.
Unter der Adminseite /admin/scheduler lässt sich die aktuelle
Konfiguration des Schedulers einsehen:

Threads versus Prozesse¶
Jobs können entweder als Prozess oder als Thread gestartet werden. In
der Defaultkonfiguration werden Jobs als Thread gestartet. Die
Defaultkonfiguration eines Jobs kann geändert werden, indem die
classlevel Variable Job.External = True gesetzt ist. Zur Laufzeit
können Jobs externalisiert werden, indem der Initialisierungsparameter
job.external = true gesetzt wird. Unter bestimmten Bedingungen ist es
besser Jobs in Prozessen als in Threads zu starten.
Threads¶
Einen Job threaded zu starten, hat den Vorteil, dass der Job schneller startet. Ein solcher Job startet im Allgemeinen in wenigen Millisekunden wenn die zugehörige Pipeline frei ist. Die Nachteile bestehen darin, dass der Job sich mit dem Hostprozess den Speicher teilt und dass der Python Interpreter nicht über mehrere Cores skaliert (Global Interpreter Lock). Ein harter Crash (Segfault) in einem threaded Job würde auch den Hostprozes terminieren. Zusammengefasst kann man sagen, dass threaded Jobs sich anbieten, wenn:
der Job so kurz läuft, dass die Startzeit nicht länger als die Laufzeit sein soll
der Job wenig CPU-intensive Operation (im Pythonspace, nicht C-Space wie Image-Transformationen) beinhaltet
der Job eher IO (DB-Operationen, Filesystem-Operationen) als CPU-lastig ist
der Job keine großen Mengen an RAM alloziert
Prozesse¶
Wenn ein Job in einem neuem Prozess gestartet wird, dann wir ein neues
VLS-Environment auf Basis der Grundkonfiguration (server.ini)
hochgefahren. Die Änderungen gegenüber der Grundkonfiguration sind in
config.server.modes.job definiert. Jeder Job kann auf class-level über
das Dictionary Job.external_cfg die Konfiguration des VLS-Environment
feiner auspezifieren.
Das Starten des VLS-Environments dauert mehrere Sekunden, von daher sollten nur Jobs externalisiert werden, die so lange laufen, dass dieser Offset vernachlässigbar ist.
Bei externen Jobs können unter Linux die Niceness-Level des Prozess
manipuliert werden. Die Level lassen sich über die
Initialisierungsparameter job.cpuPriority und job.ioPriority
steuern.
In der server.ini lassen sich unter config.job.external noch weitere
Anpassungen an dem Verhalten von externen Jobs konfigurieren.
Administrative Seiten¶
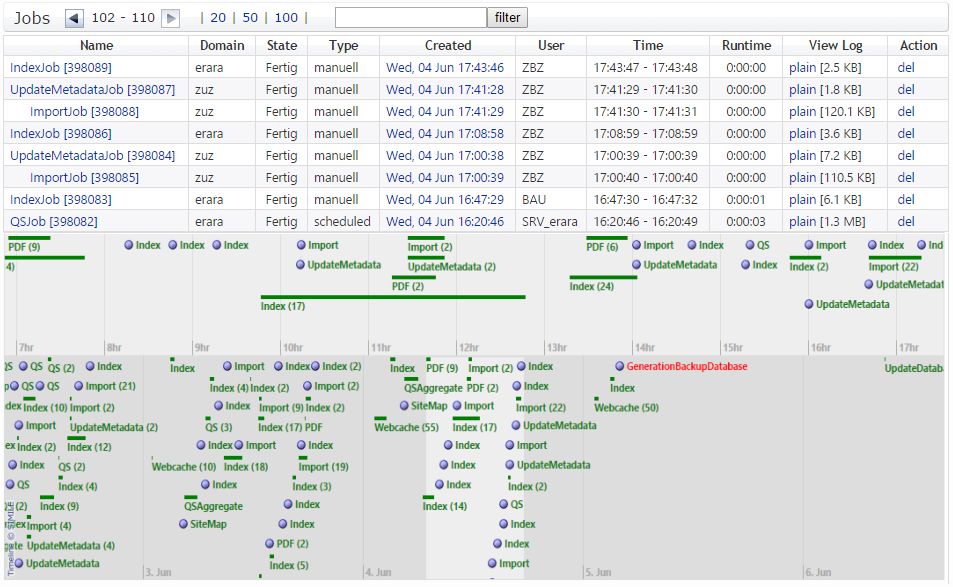
Einen Überblick über die Jobs, die, in allen Subdomains von einer
bestimmten Domain, gelaufen sind findet sich auf der Adminseite
/DOMAIN/admin/timeline. Dort wird auch, neben temporalen Eigenschaften
wie Laufzeit und Startzeitpunkt oder Erfolg bzw. Fehlschlag, die
Hierarchie zwischen verschiedenen Jobs visualisiert.
Die Details eines einzelnen Jobs lassen sich auf der Adminseite
/admin/jobreport/JOB_ID nachschlagen. Dort lässt sich das generierte
Logfile in Plaintext und eine formatierte Ansicht aller vom Job
erzeugten Events abrufen.
Pipelines¶
Die Abarbeitungsreihenfolge von Jobs wird über die Zuordnung zu Jobpipelines bestimmt. Jobs, die auf der selben Pipeline laufen, werden seriell abgearbeitet. So wird zum Beispiel verhindert, dass mehere ImportJobs gleichzeitig versuchen das primäre Importverzeichnis einer Domain abzuarbeiten. Oder, dass mehrere PDFJobs, welche relativ viel Hauptspeicher verbrauchen, gleichzeitig laufen.
Eine Pipeline wird einem Job zugewiesen indem auf class-level
Job.Pipeline=PIPELINE_NAME gesetzt wird. Eine neue Pipeline wird
eingeführt, indem einfach ein neuer PIPELINE_NAME verwendet wird. Wird
keine explizite Pipeline gesetzt, wird der Job der Pipeline mit dem
Namen default zugeordnet.
Die Pipeline mit dem Namen parallel ist eine besondere Pipeline, die,
im Gegensatz zu allen Anderen, zugeordnete Jobs gleichzeitig abarbeitet.
Zur Laufzeit kann die via class-level gesetzte Default-Pipeline
überschrieben werden, indem der Initialisierungsparameter job.pipeline
überschrieben wird.
Verwendung in Python¶
Der folgende Code zeigt das Starten des ImportJob (non-blocking) in
bestimmten Domain (ihd) eines bestimmten Server-Kontextes
(s2wp\server.ini).
from vls.core import vlsenv
from vls.api import component
plugins = 'vls.import'
with vlsenv('Q:\_server\s2wp\server.ini', plugins):
component.vls.job.startJob('ImportJob', domainName='ihd')
Bemerkung
Sollte schon ein VLS-Server auf der server.ini laufen, dann muss
server.startupChecks = False konfiguriert sein. Sonst wird der
vlsenv() Call fehlschlagen.
Der folgende Code zeigt die Implementierung eines Jobs mit Konfigurationsspezifikation:
from vls.core import vlsenv
from vls.api import component
from vls.job import Job
class NewJob(Job):
config_ini = """
option1 = integer(default=5)
# another option that is printed
option2 = string(default='')
"""
def _run(self):
for i in range(self.config.option1):
print('[%s] %s is Running!' % (i, self.config.option2))
plugins = 'vls.import'
with vlsenv('Q:\_server\s2wp\server.ini', plugins):
jobcmp = component.vls.job
jobcmp.Jobs['NewJob'] = NewJob
jobcmp.startJob('NewJob', option2='NEWJOB')